Celery Executor¶
注意
从 Airflow 2.7.0 版本开始,您需要安装 celery provider 包才能使用此执行器。这可以通过安装 apache-airflow-providers-celery>=3.3.0 或通过安装带有 celery extra 的 Airflow 来完成:pip install 'apache-airflow[celery]'。
CeleryExecutor 是您可以扩展 worker 数量的方式之一。为了使其工作,您需要设置一个 Celery 后端(RabbitMQ、Redis、Redis Sentinel…),安装所需的依赖项(例如 librabbitmq、redis…),并修改 airflow.cfg,将 executor 参数指向 CeleryExecutor 并提供相关的 Celery 设置。
有关设置 Celery broker 的更多信息,请参阅详细的Celery 相关文档。
Celery Executor 的配置参数可以在 Celery provider 的配置参考中找到。
以下是您的 worker 的几个强制性要求
需要安装
airflow,并且 CLI 需要在 path 中Airflow 配置设置在集群中应保持一致
在 worker 上执行的 Operator 需要在该上下文中满足其依赖项。例如,如果您使用
HiveOperator,则需要在该机器上安装 Hive CLI;或者如果您使用MySqlOperator,则需要以某种方式在PYTHONPATH中提供所需的 Python 库worker 需要能够访问其
DAGS_FOLDER,并且您需要通过自己的方式同步文件系统。一种常见的设置是将您的DAGS_FOLDER存储在 Git 仓库中,并使用 Chef、Puppet、Ansible 或您用于在环境中配置机器的任何工具在机器之间同步。如果您的所有机器都有一个公共挂载点,将您的管道文件共享在那里也应该可以工作
要启动一个 worker,您需要设置 Airflow 并启动 worker 子命令
airflow celery worker
您的 worker 一旦任务被发送到其方向,就应该开始接收任务。要在机器上停止正在运行的 worker,您可以使用
airflow celery stop
它将尝试通过向主 Celery 进程发送 SIGTERM 信号来优雅地停止 worker,这与 Celery 文档推荐的一样。
请注意,您还可以运行 Celery Flower(一个构建在 Celery 之上的 web UI)来监控您的 worker。您可以使用快捷命令启动一个 Flower web 服务器
airflow celery flower
请注意,您必须已在系统上安装了 flower python 库。推荐的方法是安装 airflow celery bundle。
pip install 'apache-airflow[celery]'
一些注意事项
确保使用数据库支持的结果后端
确保在
[celery_broker_transport_options]中设置一个可见性超时 (visibility timeout),该超时超过您运行时间最长任务的 ETA如果您使用 Redis Sentinel 作为 broker 并且 Redis 服务器受密码保护,请确保在
[celery_broker_transport_options]部分指定 Redis 服务器的密码确保在
[worker_umask]中设置 umask 以设置 worker 新创建文件的权限。任务会消耗资源。确保您的 worker 有足够的资源来运行
worker_concurrency任务队列名称限制为 256 个字符,但每个 broker 后端可能有自己的限制
有关 Python 和 Airflow 如何管理模块的详细信息,请参阅模块管理。
架构¶
Airflow 由几个组件组成
Workers - 执行分配的任务
Scheduler - 负责将必要的任务添加到队列中
Web server - HTTP 服务器提供访问 DAG/任务状态信息的功能
Database - 包含任务、DAG、变量、连接等的状态信息
Celery - 队列机制
请注意,Celery 的队列由两个组件组成
Broker - 存储待执行的命令
Result backend - 存储已完成命令的状态
组件在许多地方相互通信
[1] Web server –> Workers - 获取任务执行日志
[2] Web server –> DAG files - 揭示 DAG 结构
[3] Web server –> Database - 获取任务状态
[4] Workers –> DAG files - 揭示 DAG 结构并执行任务
[5] Workers –> Database - 获取并存储有关连接配置、变量和 XCOM 的信息。
[6] Workers –> Celery’s result backend - 保存任务状态
[7] Workers –> Celery’s broker - 存储待执行的命令
[8] Scheduler –> DAG files - 揭示 DAG 结构并执行任务
[9] Scheduler –> Database - 存储 DAG 运行和相关任务
[10] Scheduler –> Celery’s result backend - 获取有关已完成任务状态的信息
[11] Scheduler –> Celery’s broker - 将命令放入待执行队列
任务执行过程¶
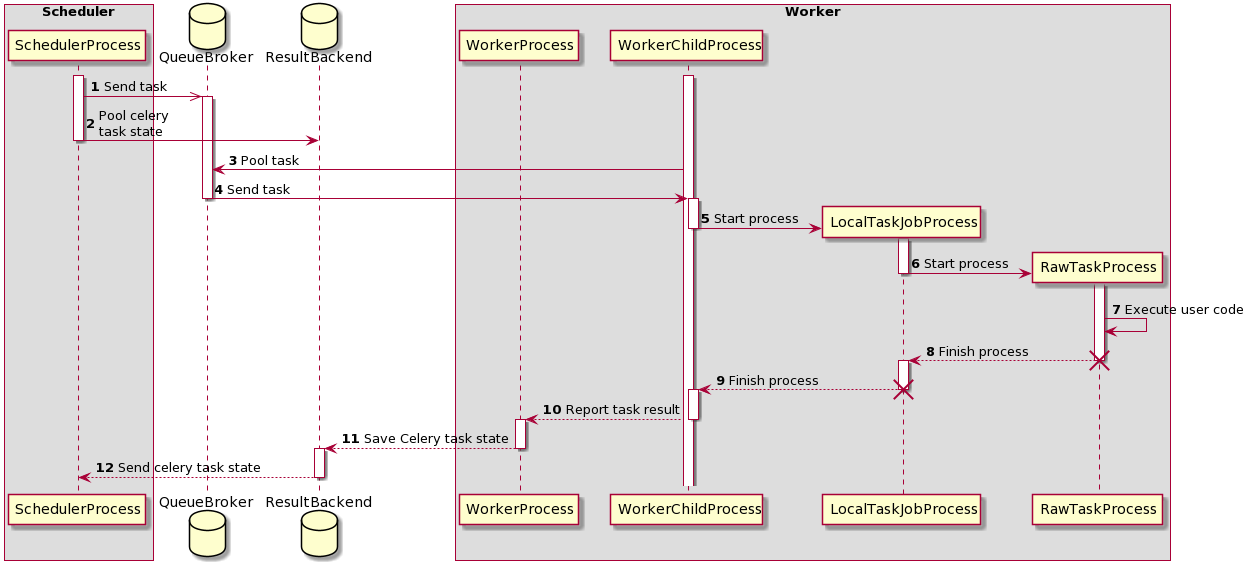
时序图 - 任务执行过程¶
最初,有两个进程正在运行
SchedulerProcess - 处理任务并使用 CeleryExecutor 运行
WorkerProcess - 监视队列等待新任务出现
WorkerChildProcess - 等待新任务
也有两个数据库可用
QueueBroker
ResultBackend
在此过程中,创建了两个进程
LocalTaskJobProcess - 其逻辑由 LocalTaskJob 描述。它监视 RawTaskProcess。新进程使用 TaskRunner 启动。
RawTaskProcess - 它是包含用户代码的进程,例如
execute()。
execute_command()。它创建一个新进程 - LocalTaskJobProcess。LocalTaskJob 类描述。它使用 TaskRunner 启动新进程。队列¶
使用 CeleryExecutor 时,可以指定将任务发送到的 Celery 队列。queue 是 BaseOperator 的一个属性,因此任何任务都可以分配给任何队列。环境的默认队列在 airflow.cfg 的 operators -> default_queue 中定义。这定义了未指定时任务被分配到的队列,以及 Airflow worker 启动时监听的队列。
Worker 可以监听一个或多个任务队列。当 worker 启动时(使用命令 airflow celery worker),可以指定一组以逗号分隔的队列名称(无空格)(例如 airflow celery worker -q spark,quark)。然后,该 worker 将仅接收分配到指定队列的任务。
如果您需要专用的 worker,这会很有用,无论从资源角度(例如对于非常轻量级的任务,一个 worker 可以轻松处理数千个任务),还是从环境角度(您希望 worker 在 Spark 集群内部运行,因为它需要非常特定的环境和安全权限)。