DAGs¶
DAG 是一种模型,封装了执行工作流所需的一切。一些 DAG 属性包括:
调度: 工作流应该何时运行。
任务: 任务 (tasks) 是在 worker 上运行的离散工作单元。
任务依赖: 任务 执行的顺序和条件。
回调: 整个工作流完成时要采取的行动。
附加参数: 以及许多其他的操作细节。
这是一个基本的 DAG 示例:
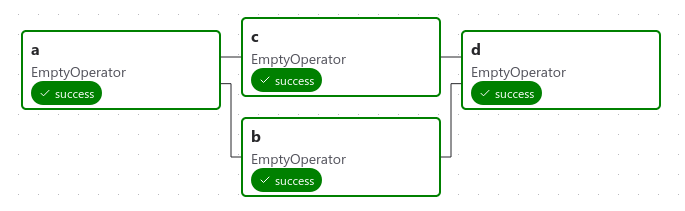
它定义了四个任务——A、B、C 和 D——并规定了它们的运行顺序,以及哪些任务依赖于其他任务。它还会说明 DAG 运行的频率——也许是“从明天开始每 5 分钟一次”,或者“从 2020 年 1 月 1 日开始每天一次”。
DAG 本身不关心任务内部正在发生*什么*;它只关心*如何*执行它们——它们的运行顺序、重试次数、是否有超时等。
注意
“DAG”一词来源于数学概念“有向无环图”,但在 Airflow 中的含义已经远远超出了与数学 DAG 概念相关的字面数据结构。
声明一个 DAG¶
有三种方法可以声明一个 DAG——你可以使用 with 语句(上下文管理器),这会将内部的一切隐式地添加到 DAG 中:
import datetime
from airflow.sdk import DAG
from airflow.providers.standard.operators.empty import EmptyOperator
with DAG(
dag_id="my_dag_name",
start_date=datetime.datetime(2021, 1, 1),
schedule="@daily",
):
EmptyOperator(task_id="task")
或者,你可以使用标准构造函数,将 DAG 传递给你使用的任何运算符:
import datetime
from airflow.sdk import DAG
from airflow.providers.standard.operators.empty import EmptyOperator
my_dag = DAG(
dag_id="my_dag_name",
start_date=datetime.datetime(2021, 1, 1),
schedule="@daily",
)
EmptyOperator(task_id="task", dag=my_dag)
或者,你可以使用 @dag 装饰器将函数 转换为 DAG 生成器:
import datetime
from airflow.sdk import dag
from airflow.providers.standard.operators.empty import EmptyOperator
@dag(start_date=datetime.datetime(2021, 1, 1), schedule="@daily")
def generate_dag():
EmptyOperator(task_id="task")
generate_dag()
没有要运行的任务,DAG 就什么都不是,而这些任务通常以 运算符 (Operators)、传感器 (Sensors) 或 TaskFlow 的形式出现。
任务依赖¶
任务/运算符通常不会单独存在;它依赖于其他任务(位于它*上游*的任务),其他任务也依赖于它(位于它*下游*的任务)。声明这些任务之间的依赖关系构成了 DAG 结构(有向无环图的*边*)。
有两种主要方法来声明单个任务依赖关系。推荐的方法是使用 >> 和 << 运算符:
first_task >> [second_task, third_task]
third_task << fourth_task
或者,你也可以使用更明确的 set_upstream 和 set_downstream 方法:
first_task.set_downstream([second_task, third_task])
third_task.set_upstream(fourth_task)
还有一些声明更复杂依赖关系的快捷方式。如果你想让一个任务列表依赖于另一个任务列表,你就不能使用上面两种方法,因此需要使用 cross_downstream:
from airflow.sdk import cross_downstream
# Replaces
# [op1, op2] >> op3
# [op1, op2] >> op4
cross_downstream([op1, op2], [op3, op4])
如果你想将依赖关系链接起来,可以使用 chain:
from airflow.sdk import chain
# Replaces op1 >> op2 >> op3 >> op4
chain(op1, op2, op3, op4)
# You can also do it dynamically
chain(*[EmptyOperator(task_id=f"op{i}") for i in range(1, 6)])
chain 也可以对大小相同的列表进行*成对*依赖(这与 cross_downstream 创建的*交叉依赖*不同!):
from airflow.sdk import chain
# Replaces
# op1 >> op2 >> op4 >> op6
# op1 >> op3 >> op5 >> op6
chain(op1, [op2, op3], [op4, op5], op6)
加载 DAG¶
Airflow 从 DAG 包中的 Python 源文件加载 DAG。它会获取每个文件,执行它,然后从该文件中加载任何 DAG 对象。
这意味着你可以在一个 Python 文件中定义多个 DAG,甚至可以使用导入功能将一个非常复杂的 DAG 分散到多个 Python 文件中。
但请注意,当 Airflow 从 Python 文件加载 DAG 时,它只会拉取位于*顶层*且是 DAG 实例的任何对象。例如,考虑这个 DAG 文件:
dag_1 = DAG('this_dag_will_be_discovered')
def my_function():
dag_2 = DAG('but_this_dag_will_not')
my_function()
虽然文件被访问时会调用两个 DAG 构造函数,但只有 dag_1 位于顶层(在 globals() 中),因此只有它被添加到 Airflow 中。dag_2 未被加载。
注意
作为一种优化,当在 DAG 包中搜索 DAG 时,Airflow 只考虑包含字符串 airflow 和 dag(不区分大小写)的 Python 文件。
要考虑所有 Python 文件,请禁用 DAG_DISCOVERY_SAFE_MODE 配置标志。
你还可以在 DAG 包或其任何子文件夹中提供一个 .airflowignore 文件,该文件描述了加载器要忽略的文件模式。它涵盖了所在目录及其下的所有子文件夹。有关文件语法的详细信息,请参阅下面的.airflowignore。
如果 .airflowignore 无法满足你的需求,并且你想要一种更灵活的方式来控制 Airflow 是否需要解析某个 Python 文件,你可以通过在配置文件中设置 might_contain_dag_callable 来插入你的可调用对象。请注意,此可调用对象将替换默认的 Airflow 启发式方法,即检查 Python 文件中是否存在字符串 airflow 和 dag(不区分大小写)。
def might_contain_dag(file_path: str, zip_file: zipfile.ZipFile | None = None) -> bool:
# Your logic to check if there are dags defined in the file_path
# Return True if the file_path needs to be parsed, otherwise False
运行 DAG¶
DAG 将以下列两种方式之一运行:
当它们被手动或通过 API *触发*时。
按照 DAG 定义的*调度*运行。
DAG *不要求*有调度,但定义调度非常常见。你可以通过 schedule 参数来定义它,如下所示:
with DAG("my_daily_dag", schedule="@daily"):
...
schedule 参数有多种有效值:
with DAG("my_daily_dag", schedule="0 0 * * *"):
...
with DAG("my_one_time_dag", schedule="@once"):
...
with DAG("my_continuous_dag", schedule="@continuous"):
...
提示
有关不同类型调度的更多信息,请参阅编写和调度。
每次运行 DAG 时,都会创建一个新的 DAG 实例,Airflow 将其称为DAG 运行 (DAG Run)。同一个 DAG 可以并行运行多个 DAG 运行,每个 DAG 运行都有一个定义的数据间隔 (data interval),用于标识任务应该处理的数据期间。
举个例子说明为何这很有用:考虑编写一个处理每日实验数据的 DAG。它已被重写,你想对前 3 个月的数据运行它——没问题,因为 Airflow 可以*回填 (backfill)* DAG,并对这前 3 个月的每一天都运行一份副本,所有副本同时运行。
所有这些 DAG 运行都在同一天实际开始,但每个 DAG 运行都有一个数据间隔,涵盖这 3 个月期间的单一天,而这个数据间隔是 DAG 内部所有任务、运算符和传感器运行时所关注的全部。
就像 DAG 每次运行时都会实例化为一个 DAG 运行一样,DAG 内指定的任务也会随之实例化为任务实例 (Task Instances)。
DAG 运行有开始日期和结束日期。这个期间描述了 DAG 实际“运行”的时间。除了 DAG 运行的开始和结束日期外,还有一个称为*逻辑日期 (logical date)*(正式名称为执行日期 (execution date))的日期,它描述了 DAG 运行计划或触发的预期时间。之所以称为*逻辑*,是因为它具有抽象性,取决于 DAG 运行的上下文,可能具有多种含义。
例如,如果 DAG 运行由用户手动触发,则其逻辑日期将是 DAG 运行触发的日期和时间,其值应等于 DAG 运行的开始日期。然而,当 DAG 根据设定的调度间隔自动调度时,逻辑日期将指示数据间隔开始的时间点,此时 DAG 运行的开始日期将是逻辑日期 + 调度间隔。
提示
有关 logical date 的更多信息,请参阅数据间隔 (Data Interval) 和execution_date 是什么意思?。
DAG 分配¶
请注意,为了运行,每个运算符/任务都必须分配给一个 DAG。Airflow 有几种方法可以在不显式传递 DAG 的情况下计算出它:
如果你在
with DAG块内声明你的运算符:如果你在
@dag装饰器内声明你的运算符:如果你将你的运算符放在已分配 DAG 的运算符的上游或下游:
否则,你必须使用 dag= 将其传递给每个运算符。
默认参数¶
通常,DAG 中的许多运算符需要一组相同的默认参数(例如它们的 retries)。与其为每个运算符单独指定这些参数,你可以在创建 DAG 时传递 default_args,它将自动应用于与其关联的任何运算符:
import pendulum
with DAG(
dag_id="my_dag",
start_date=pendulum.datetime(2016, 1, 1),
schedule="@daily",
default_args={"retries": 2},
):
op = BashOperator(task_id="hello_world", bash_command="Hello World!")
print(op.retries) # 2
DAG 装饰器¶
添加于 2.0 版本。
除了使用上下文管理器或 DAG() 构造函数声明单个 DAG 的传统方式外,你还可以使用 @dag 装饰器装饰一个函数,将其转换为 DAG 生成器函数:
src/airflow/example_dags/example_dag_decorator.py
@dag(
schedule=None,
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example"],
)
def example_dag_decorator(url: str = "http://httpbin.org/get"):
"""
DAG to get IP address and echo it via BashOperator.
:param url: URL to get IP address from. Defaults to "http://httpbin.org/get".
"""
get_ip = GetRequestOperator(task_id="get_ip", url=url)
@task(multiple_outputs=True)
def prepare_command(raw_json: dict[str, Any]) -> dict[str, str]:
external_ip = raw_json["origin"]
return {
"command": f"echo 'Seems like today your server executing Airflow is connected from IP {external_ip}'",
}
command_info = prepare_command(get_ip.output)
BashOperator(task_id="echo_ip_info", bash_command=command_info["command"])
example_dag = example_dag_decorator()
除了作为一种新的干净地创建 DAG 的方式外,装饰器还会将函数中的任何参数设置为 DAG 参数,允许你在触发 DAG 时设置这些参数。然后你可以从 Python 代码或 Jinja 模板中的 {{ context.params }} 访问这些参数。
注意
Airflow 只会加载出现在 DAG 文件顶层的 DAG。这意味着你不能只声明一个带有 @dag 的函数——你还必须在你的 DAG 文件中至少调用它一次,并将其分配给一个顶层对象,如上面的示例所示。
控制流¶
默认情况下,只有当一个任务的所有依赖任务都成功时,DAG 才会运行该任务。但是,有几种方法可以修改这种行为:
分支 (Branching) - 根据条件选择要进入哪个任务。
触发规则 (Trigger Rules) - 设置 DAG 运行任务的条件。
设置和拆卸 (Setup and Teardown) - 定义设置和拆卸关系。
仅最新 (Latest Only) - 一种特殊形式的分支,只在针对当前时间运行的 DAGs 上运行。
依赖于过去 (Depends On Past) - 任务可以*依赖于它自身在之前的运行*。
分支¶
你可以利用分支来告诉 DAG *不要*运行所有依赖任务,而是选择一条或多条路径进行。这时就用到了 @task.branch 装饰器。
@task.branch 装饰器非常像 @task,但它期望被装饰的函数返回一个任务的 ID(或一个 ID 列表)。指定的任务将被执行,而所有其他路径将被跳过。它也可以返回 *None* 来跳过所有下游任务。
Python 函数返回的 task_id 必须引用 @task.branch 装饰的任务直接下游的任务。
注意
当一个任务既是分支操作符的下游,又是被选中的一个或多个任务的下游时,它将不会被跳过:
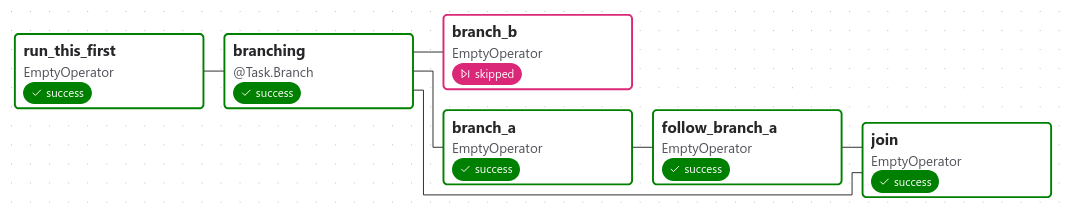
分支任务的路径是 branch_a、join 和 branch_b。由于 join 是 branch_a 的下游任务,即使它没有作为分支决策的一部分返回,它仍然会运行。
@task.branch 也可以与 XComs 一起使用,允许分支上下文根据上游任务动态决定要遵循哪个分支。例如:
@task.branch(task_id="branch_task")
def branch_func(ti=None):
xcom_value = int(ti.xcom_pull(task_ids="start_task"))
if xcom_value >= 5:
return "continue_task"
elif xcom_value >= 3:
return "stop_task"
else:
return None
start_op = BashOperator(
task_id="start_task",
bash_command="echo 5",
do_xcom_push=True,
dag=dag,
)
branch_op = branch_func()
continue_op = EmptyOperator(task_id="continue_task", dag=dag)
stop_op = EmptyOperator(task_id="stop_task", dag=dag)
start_op >> branch_op >> [continue_op, stop_op]
如果你希望实现带有分支功能的自定义运算符,可以从 BaseBranchOperator 继承,它的行为类似于 @task.branch 装饰器,但需要你提供 choose_branch 方法的实现。
注意
建议优先使用 @task.branch 装饰器,而不是直接在 DAG 中实例化 BranchPythonOperator。后者通常只应在实现自定义运算符时进行子类化。
与 @task.branch 的可调用对象一样,此方法可以返回下游任务的 ID 或任务 ID 列表,这些任务将运行,而其他所有任务将被跳过。它也可以返回 None 以跳过所有下游任务:
class MyBranchOperator(BaseBranchOperator):
def choose_branch(self, context):
"""
Run an extra branch on the first day of the month
"""
if context['data_interval_start'].day == 1:
return ['daily_task_id', 'monthly_task_id']
elif context['data_interval_start'].day == 2:
return 'daily_task_id'
else:
return None
类似于用于常规 Python 代码的 @task.branch 装饰器,还有使用虚拟环境的 @task.branch_virtualenv 或使用外部 Python 的 @task.branch_external_python 分支装饰器。
仅最新¶
Airflow 的 DAG 运行通常针对的日期与当前日期不同——例如,对上个月的每一天运行一份 DAG 副本,以回填一些数据。
但是,在某些情况下,你*不*希望 DAG 的某些(或所有)部分针对过去的日期运行;在这种情况下,你可以使用 LatestOnlyOperator。
这个特殊的运算符会在你不在“最新”的 DAG 运行时(如果当前真实时间在其执行时间 (execution_time) 和下一次计划执行时间之间,且不是外部触发的运行)跳过其下游的所有任务。
这里有一个例子:
src/airflow/example_dags/example_latest_only_with_trigger.py
import datetime
import pendulum
from airflow.providers.standard.operators.empty import EmptyOperator
from airflow.providers.standard.operators.latest_only import LatestOnlyOperator
from airflow.sdk import DAG
from airflow.utils.trigger_rule import TriggerRule
with DAG(
dag_id="latest_only_with_trigger",
schedule=datetime.timedelta(hours=4),
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
tags=["example3"],
) as dag:
latest_only = LatestOnlyOperator(task_id="latest_only")
task1 = EmptyOperator(task_id="task1")
task2 = EmptyOperator(task_id="task2")
task3 = EmptyOperator(task_id="task3")
task4 = EmptyOperator(task_id="task4", trigger_rule=TriggerRule.ALL_DONE)
latest_only >> task1 >> [task3, task4]
task2 >> [task3, task4]
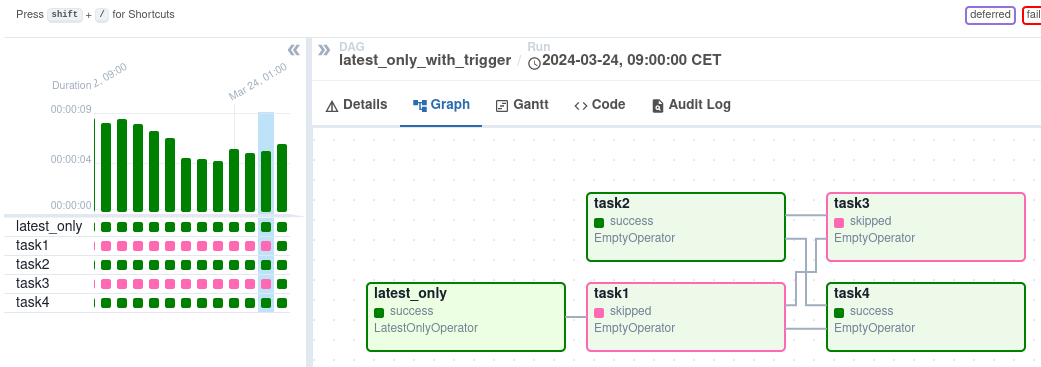
在这个 DAG 的情况下:
task1是latest_only的直接下游,除了最新的运行外,所有运行都会跳过它。task2完全独立于latest_only,将在所有计划周期中运行。task3是task1和task2的下游,由于默认的触发规则 (trigger rule) 是all_success,它将收到来自task1的级联跳过。task4是task1和task2的下游,但它不会被跳过,因为其trigger_rule设置为all_done。
依赖于过去¶
你也可以说一个任务只有在其在先前 DAG 运行中的*上一次*运行成功时才能运行。要使用此功能,你只需将任务的 depends_on_past 参数设置为 True。
请注意,如果你在 DAG 生命周期的最开始运行它——特别是它的第一次*自动化*运行——那么该任务仍将运行,因为它没有之前的运行可以依赖。
触发规则¶
默认情况下,Airflow 会等待一个任务的所有上游(直接父任务)任务都处于成功状态后才运行该任务。
然而,这只是默认行为,你可以使用任务的 trigger_rule 参数来控制它。trigger_rule 的选项包括:
all_success(默认): 所有上游任务都已成功。all_failed: 所有上游任务都处于failed或upstream_failed状态。all_done: 所有上游任务都已完成执行。all_skipped: 所有上游任务都处于skipped状态。one_failed: 至少有一个上游任务失败(不等待所有上游任务完成)。one_success: 至少有一个上游任务成功(不等待所有上游任务完成)。one_done: 至少有一个上游任务成功或失败。none_failed: 所有上游任务都没有failed或upstream_failed——也就是说,所有上游任务都已成功或被跳过。none_failed_min_one_success: 所有上游任务都没有failed或upstream_failed,并且至少有一个上游任务成功。none_skipped: 没有上游任务处于skipped状态——也就是说,所有上游任务都处于success、failed或upstream_failed状态。always: 完全没有依赖关系,随时运行此任务。
如果需要,你还可以将其与依赖于过去 (Depends On Past) 功能结合使用。
注意
重要的是要意识到触发规则与被跳过任务之间的相互作用,特别是作为分支操作一部分被跳过的任务。*在分支操作的下游,几乎永远不要使用 all_success 或 all_failed*。
被跳过的任务将通过触发规则 all_success 和 all_failed 进行级联,导致它们也被跳过。考虑以下 DAG:
# dags/branch_without_trigger.py
import pendulum
from airflow.sdk import task
from airflow.sdk import DAG
from airflow.providers.standard.operators.empty import EmptyOperator
dag = DAG(
dag_id="branch_without_trigger",
schedule="@once",
start_date=pendulum.datetime(2019, 2, 28, tz="UTC"),
)
run_this_first = EmptyOperator(task_id="run_this_first", dag=dag)
@task.branch(task_id="branching")
def do_branching():
return "branch_a"
branching = do_branching()
branch_a = EmptyOperator(task_id="branch_a", dag=dag)
follow_branch_a = EmptyOperator(task_id="follow_branch_a", dag=dag)
branch_false = EmptyOperator(task_id="branch_false", dag=dag)
join = EmptyOperator(task_id="join", dag=dag)
run_this_first >> branching
branching >> branch_a >> follow_branch_a >> join
branching >> branch_false >> join
join 位于 follow_branch_a 和 branch_false 的下游。join 任务将显示为已跳过,因为其 trigger_rule 默认为 all_success,并且分支操作导致的跳过会级联到标记为 all_success 的任务。

通过将 join 任务中的 trigger_rule 设置为 none_failed_min_one_success,我们可以获得预期的行为:

设置和拆卸¶
在数据工作流中,创建资源(例如计算资源),使用它完成一些工作,然后将其拆卸是很常见的。Airflow 提供设置和拆卸任务来支持此需求。
请参阅主要文章设置和拆卸,了解如何使用此功能。
动态 DAG¶
由于 DAG 由 Python 代码定义,因此无需使其完全声明式;你可以自由使用循环、函数等来定义你的 DAG。
例如,这是一个使用 for 循环定义一些任务的 DAG:
with DAG("loop_example", ...):
first = EmptyOperator(task_id="first")
last = EmptyOperator(task_id="last")
options = ["branch_a", "branch_b", "branch_c", "branch_d"]
for option in options:
t = EmptyOperator(task_id=option)
first >> t >> last
一般来说,我们建议你尽量保持 DAG 任务的*拓扑结构*(布局)相对稳定;动态 DAG 通常更适合用于动态加载配置选项或更改运算符选项。
DAG 可视化¶
如果你想查看 DAG 的可视化表示,有两种选择:
你可以打开 Airflow UI,导航到你的 DAG,然后选择“图表” (Graph)。
你可以运行
airflow dags show,它会将其渲染为图像文件。
我们通常建议你使用图表视图 (Graph view),因为它还会显示你选择的任何 DAG 运行中所有任务实例 (Task Instances) 的状态。
当然,随着你的 DAG 变得越来越复杂,它们会变得越来越难以理解,因此我们提供了几种修改这些 DAG 视图的方法,使它们更容易理解。
TaskGroups¶
TaskGroup 可用于在图表视图 (Graph view) 中将任务组织成层次结构组。它对于创建重复模式和减少视觉混乱很有用。
TaskGroup 中的任务位于同一原始 DAG 上,并遵循所有 DAG 设置和池配置。
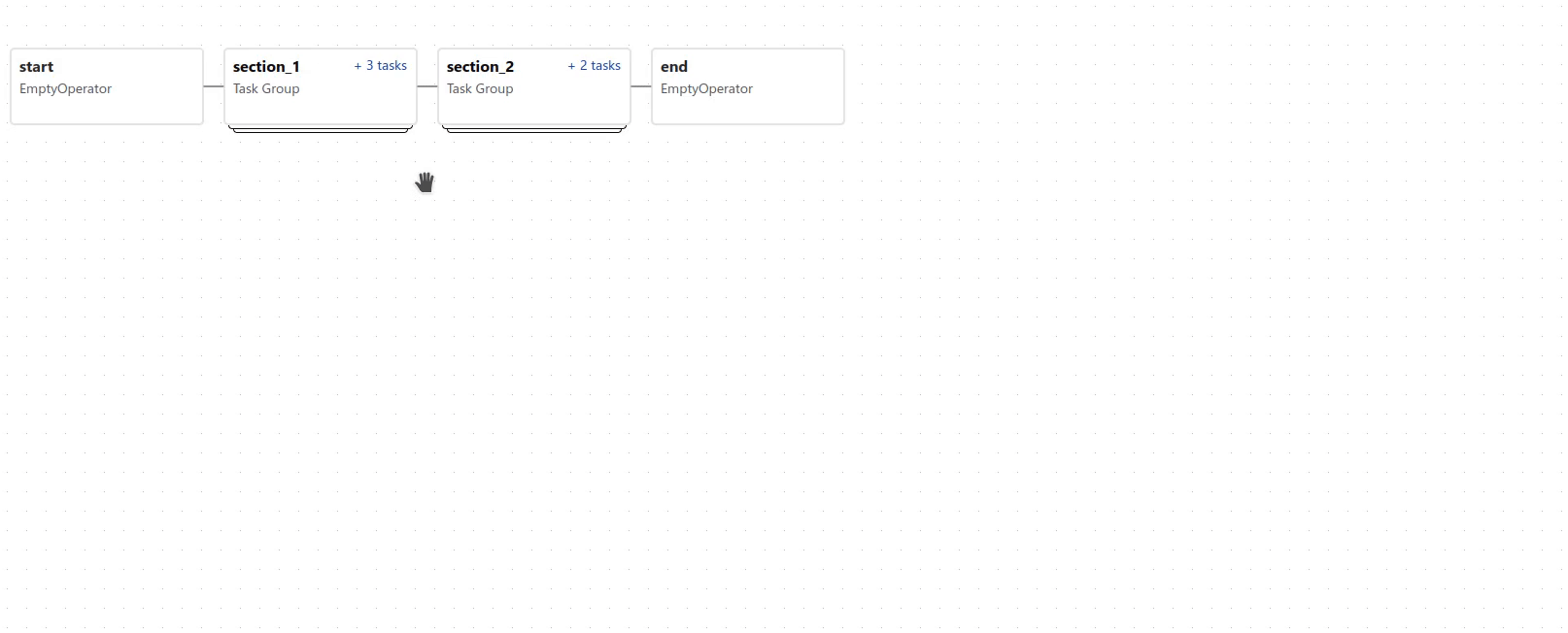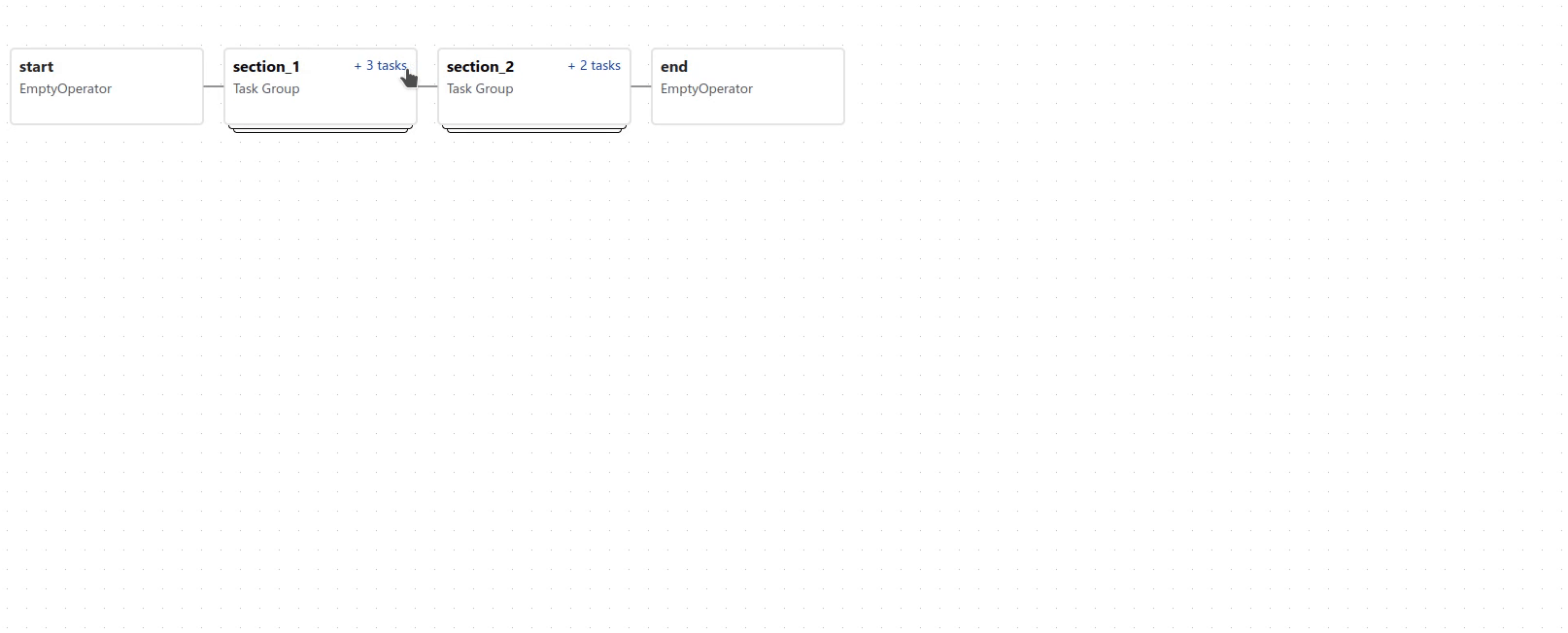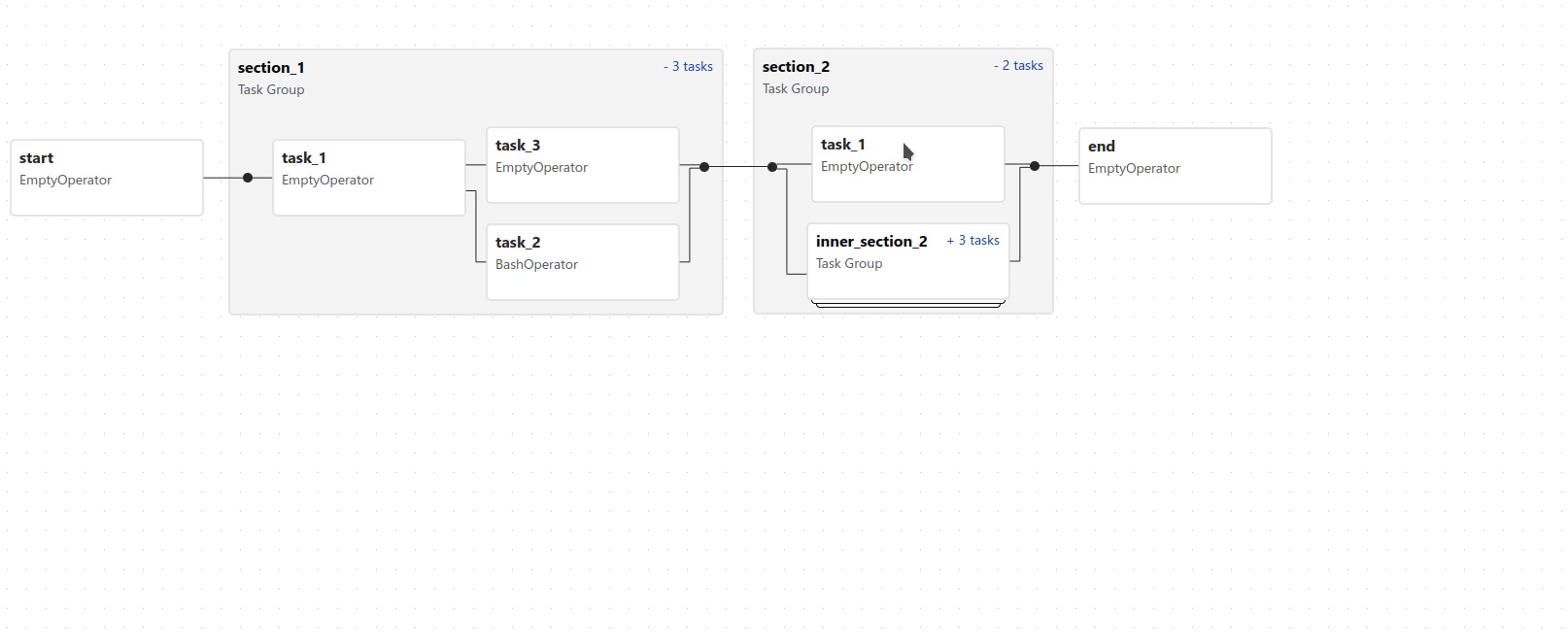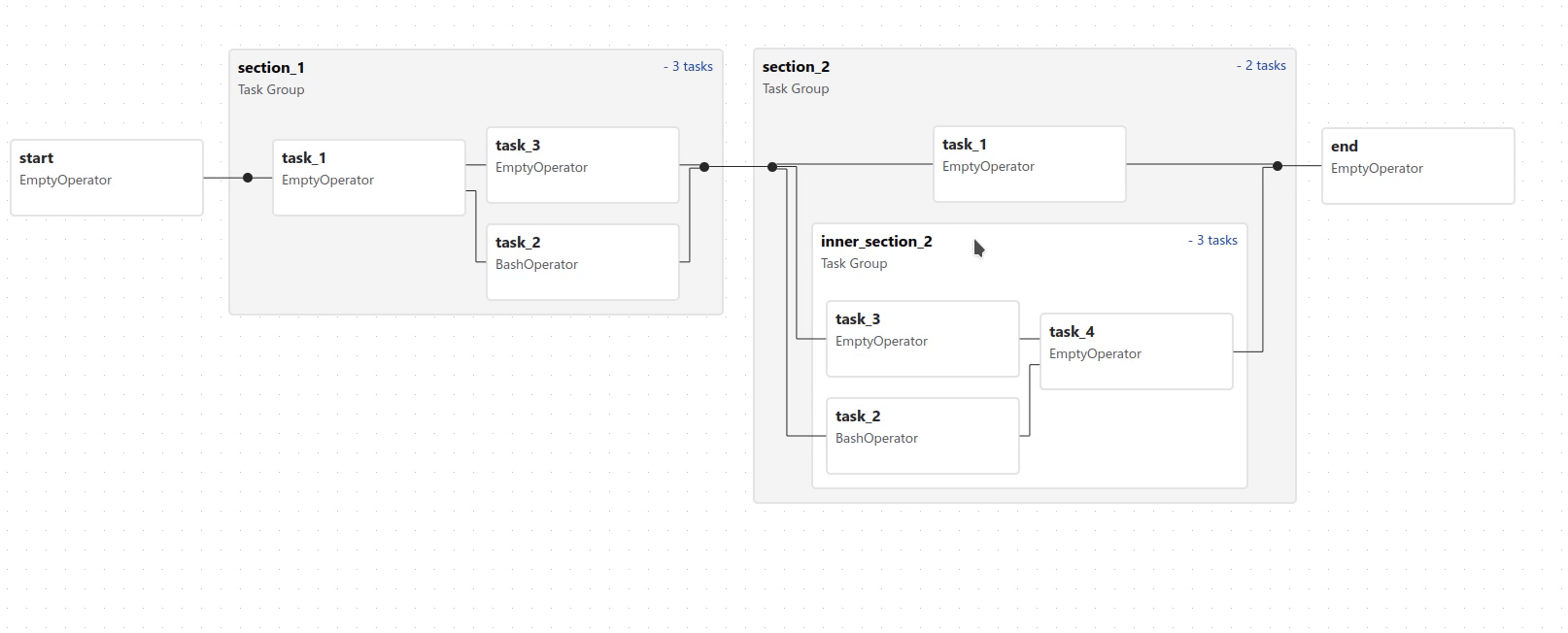
可以使用 >> 和 << 运算符跨 TaskGroup 中的所有任务应用依赖关系。例如,以下代码将 task1 和 task2 放入 TaskGroup group1 中,然后将这两个任务都设置为 task3 的上游:
from airflow.sdk import task_group
@task_group()
def group1():
task1 = EmptyOperator(task_id="task1")
task2 = EmptyOperator(task_id="task2")
task3 = EmptyOperator(task_id="task3")
group1() >> task3
TaskGroup 也支持 default_args,就像 DAG 一样,它会覆盖 DAG 级别的 default_args。
import datetime
from airflow.sdk import DAG
from airflow.sdk import task_group
from airflow.providers.standard.operators.bash import BashOperator
from airflow.providers.standard.operators.empty import EmptyOperator
with DAG(
dag_id="dag1",
start_date=datetime.datetime(2016, 1, 1),
schedule="@daily",
default_args={"retries": 1},
):
@task_group(default_args={"retries": 3})
def group1():
"""This docstring will become the tooltip for the TaskGroup."""
task1 = EmptyOperator(task_id="task1")
task2 = BashOperator(task_id="task2", bash_command="echo Hello World!", retries=2)
print(task1.retries) # 3
print(task2.retries) # 2
如果你想了解 TaskGroup 的更高级用法,可以查看 Airflow 自带的 example_task_group_decorator.py 示例 DAG。
注意
默认情况下,子任务/TaskGroup 的 ID 会以其父 TaskGroup 的 group_id 作为前缀。这有助于确保整个 DAG 中 group_id 和 task_id 的唯一性。
要禁用此前缀行为,在创建 TaskGroup 时传递参数 prefix_group_id=False,但请注意,现在你需要自己负责确保每个任务和组都具有唯一的 ID。
注意
当使用 @task_group 装饰器时,除非显式提供了 tooltip 值,否则被装饰函数的文档字符串(docstring)将用作 UI 中 TaskGroup 的工具提示(tooltip)。
边缘标签 (Edge Labels)¶
除了将任务分组之外,你还可以在“图视图”(Graph view)中为不同任务之间的*依赖边缘*添加标签——这对于 DAG 的分支区域特别有用,你可以标注某些分支可能运行的条件。
要添加标签,可以直接在 >> 和 << 运算符中以内联方式使用它们
from airflow.sdk import Label
my_task >> Label("When empty") >> other_task
或者,你可以将一个 Label 对象传递给 set_upstream/set_downstream 方法
from airflow.sdk import Label
my_task.set_downstream(other_task, Label("When empty"))
这是一个说明如何标注不同分支的示例 DAG

src/airflow/example_dags/example_branch_labels.py
with DAG(
"example_branch_labels",
schedule="@daily",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
catchup=False,
) as dag:
ingest = EmptyOperator(task_id="ingest")
analyse = EmptyOperator(task_id="analyze")
check = EmptyOperator(task_id="check_integrity")
describe = EmptyOperator(task_id="describe_integrity")
error = EmptyOperator(task_id="email_error")
save = EmptyOperator(task_id="save")
report = EmptyOperator(task_id="report")
ingest >> analyse >> check
check >> Label("No errors") >> save >> report
check >> Label("Errors found") >> describe >> error >> report
DAG 与任务文档 (DAG & Task Documentation)¶
你可以为你的 DAG 和任务对象添加文档或备注,这些内容可以在 Web 界面中看到(DAG 对应“Graph”和“Tree”,任务对应“Task Instance Details”)。
如果定义了以下一组特殊的任务属性,它们将被渲染为富文本内容
属性 |
渲染为 |
|---|---|
doc |
等宽字体 |
doc_json |
json |
doc_yaml |
yaml |
doc_md |
markdown |
doc_rst |
reStructuredText |
请注意,对于 DAG 而言,只有 doc_md 属性会被解析。对于 DAG,它可以包含一个字符串或指向 markdown 文件的引用。markdown 文件通过以 .md 结尾的字符串来识别。如果提供的是相对路径,文件将从 Airflow Scheduler 或 DAG 解析器启动的相对路径加载。如果 markdown 文件不存在,传递的文件名将被用作文本,不会显示异常。请注意,markdown 文件是在 DAG 解析期间加载的,对其内容的更改需要经过一个 DAG 解析周期才能显示。
如果你的任务是从配置文件动态构建的,这会特别有用,因为它允许你在 Airflow 中展示生成相关任务的配置。
"""
### My great DAG
"""
import pendulum
dag = DAG(
"my_dag",
start_date=pendulum.datetime(2021, 1, 1, tz="UTC"),
schedule="@daily",
catchup=False,
)
dag.doc_md = __doc__
t = BashOperator("foo", dag=dag)
t.doc_md = """\
#Title"
Here's a [url](www.airbnb.com)
"""
打包 DAG (Packaging dags)¶
虽然简单的 DAG 通常只包含在一个 Python 文件中,但更复杂的 DAG 分布在多个文件并包含应随其一起分发(“vendored”)的依赖项也很常见。
你可以在 DAG 捆绑包内部完成所有这些,使用标准的 文件系统布局,或者你可以将 DAG 及其所有 Python 文件打包成一个单独的 zip 文件。例如,你可以将两个 DAG 和它们所需的一个依赖项打包成一个 zip 文件,其内容如下:
my_dag1.py
my_dag2.py
package1/__init__.py
package1/functions.py
请注意,打包的 DAG 存在一些限制:
如果为序列化启用了 pickling,则无法使用它们
它们不能包含编译后的库(例如
libz.so),只能包含纯 Python 文件它们将被插入到 Python 的
sys.path中,并可供 Airflow 进程中的任何其他代码导入,因此请确保包名不会与系统上已安装的其他包冲突。
总的来说,如果你有一组复杂的编译依赖项和模块,使用 Python 的 virtualenv 系统并通过 pip 在目标系统上安装必要的包可能是更好的选择。
.airflowignore¶
.airflowignore 文件指定了 Airflow 应该故意忽略的 DAG 捆绑包或 PLUGINS_FOLDER 中的目录或文件。 Airflow 支持文件中的两种模式语法,由 DAG_IGNORE_FILE_SYNTAX 配置参数指定(*在 Airflow 2.3 中添加*):regexp 和 glob。
注意
在 Airflow 3 或更高版本中,默认的 DAG_IGNORE_FILE_SYNTAX 是 glob(在早期版本中是 regexp)。
使用 glob 语法(默认),模式的工作方式与 .gitignore 文件中的模式类似:
*字符匹配任意数量的字符,但不包括/?字符匹配任意单个字符,但不包括/范围表示法,例如
[a-zA-Z],可用于匹配范围内的任一字符通过在模式前加上
!可以否定该模式。模式按顺序评估,因此否定可以覆盖同一文件中先前定义的模式或父目录中定义的模式。双星号(
**)可用于匹配跨目录的文件/路径。例如,**/__pycache__/将忽略每个子目录中的__pycache__目录,深度不限。如果模式开头或中间(或两者都有)包含
/,则该模式是相对于.airflowignore文件所在的目录级别。否则,该模式也可能匹配.airflowignore文件所在目录级别下的任何级别。
对于 regexp 模式语法,.airflowignore 文件中的每一行都指定一个正则表达式模式,其名称(而非 DAG ID)匹配任一模式的目录或文件将被忽略(底层实现使用 Pattern.search() 来匹配模式)。使用 # 字符表示注释;以 # 开头的行的所有字符都将被忽略。
.airflowignore 文件应该放在你的 DAG 捆绑包中。例如,你可以准备一个使用 glob 语法的 .airflowignore 文件:
**/*project_a*
tenant_[0-9]*
那么你的 DAG 捆绑包中诸如 project_a_dag_1.py、TESTING_project_a.py、tenant_1.py、project_a/dag_1.py 和 tenant_1/dag_1.py 等文件将被忽略(如果目录名称匹配任一模式,则该目录及其所有子文件夹将完全不被 Airflow 扫描。这提高了 DAG 查找的效率)。
.airflowignore 文件的作用范围是其所在的目录及其所有子文件夹。你也可以为 DAG 捆绑包中的一个子文件夹准备 .airflowignore 文件,它将仅适用于该子文件夹。
DAG 依赖关系 (DAG Dependencies)¶
在 Airflow 2.1 中添加
DAG 中任务之间的依赖关系通过上游和下游关系明确定义,而 DAG 之间的依赖关系则稍微复杂一些。总的来说,一个 DAG 可以依赖于另一个 DAG 的方式有两种:
等待 -
ExternalTaskSensor
额外的复杂性在于,一个 DAG 可能需要等待或触发另一个 DAG 的多次运行,且数据间隔可能不同。**DAG 依赖关系**视图(菜单 -> 浏览 -> DAG 依赖关系)有助于可视化 DAG 之间的依赖关系。这些依赖关系由调度器在 DAG 序列化期间计算,Web 服务器使用它们来构建依赖图。
依赖检测器是可配置的,因此你可以实现自己的逻辑,与 DependencyDetector 中的默认逻辑不同。
DAG 暂停、停用和删除 (DAG pausing, deactivation and deletion)¶
DAG 在处于“未运行”状态时有几种不同的状态。DAG 可以被暂停(paused)、停用(deactivated),最后可以删除 DAG 的所有元数据。
DAG 可以在 UI 中被暂停(paused),当它存在于 DAGS_FOLDER 中且调度器已将其存储在数据库中,但用户选择通过 UI 禁用它。通过 UI 和 API 可以执行“暂停”(pause)和“取消暂停”(unpause)操作。被暂停的 DAG 不会被调度器安排运行,但你可以通过 UI 手动触发它们。在 UI 中,你可以在“Paused”标签页中看到已暂停的 DAG。未暂停的 DAG 可以在“Active”标签页中找到。当一个 DAG 被暂停时,任何正在运行的任务将被允许完成,所有下游任务将被置于“Scheduled”(已调度)状态。当 DAG 取消暂停时,任何处于“Scheduled”状态的任务将按照 DAG 逻辑开始运行。没有“Scheduled”任务的 DAG 将按照其调度计划开始运行。
DAG 可以通过从 DAGS_FOLDER 中移除文件来停用(deactivated)(不要与 UI 中的“Active”标签混淆)。当调度器解析 DAGS_FOLDER 并发现之前见过且存储在数据库中的某个 DAG 不存在时,它会将其设置为停用状态。已停用的 DAG 会保留其元数据和历史记录;当该 DAG 被重新添加回 DAGS_FOLDER 时,它会再次被激活,并且历史记录将可见。你无法通过 UI 或 API 激活/停用 DAG,这只能通过从 DAGS_FOLDER 中移除文件来完成。再次强调 - 当 DAG 被调度器停用时,其历史运行数据不会丢失。请注意,Airflow UI 中的“Active”标签页指的是既已“Activated”且未“Paused”的 DAG,这一点最初可能会有点令人困惑。
你无法在 UI 中看到已停用的 DAG——有时你可以看到历史运行记录,但当你尝试查看相关信息时,会看到 DAG 不存在的错误。
你还可以使用 UI 或 API 从元数据数据库中删除 DAG 的元数据,但这并不总会导致 DAG 从 UI 中消失——这一点最初可能也会有点令人困惑。如果你删除元数据时 DAG 仍然在 DAGS_FOLDER 中,调度器会重新解析该文件夹,DAG 将再次出现,只是该 DAG 的历史运行信息会被移除。
这意味着如果你想实际删除一个 DAG 及其所有历史元数据,你需要分三步进行:
暂停 DAG。
通过 UI 或 API 从数据库中删除历史元数据。
从
DAGS_FOLDER中删除 DAG 文件,并等待其变为非活动状态。
DAG 自动暂停 (Experimental)¶
DAG 也可以配置为自动暂停。Airflow 有一个配置项,允许在 DAG 连续失败 N 次后自动禁用它。
我们也可以从 DAG 参数中提供并覆盖这些配置:
max_consecutive_failed_dag_runs:覆盖 max_consecutive_failed_dag_runs_per_dag 配置。